While reading “The Art of Memory Forensics”, I came across a plugin the authors wrote to read the text inserted in a Notepad.exe instance off of process memory. While just an example, I figured I would try to implement the plugin myself to familiarize with Volatility internal workings. There were mainly two issues to overcome:
- An actual plugin implementation is never given in the book, nor can be easily found online,
- The book was written in 2014 and focuses on Volatility 2. I wanted to write my code for Volatility 3, and I wanted it to work on newer versions of Windows.
The first thing I needed to do, was to generate a memory dump that I could work off of. To do that I just started a notepad instance on a Windows 10 VM, added some text (without saving to disk!) and captured the memory content with FTK Imager.
After obtaining the memory dump, it was time to start writing the plugin. On a general level, the plugin is meant to work similarly as described in the book. First, it should identify the PID of the process where ImageBaseFile=="notepad.exe". Then it should list all of the Virtual Address Descriptors (VAD) for the process, and search them for the text we wrote in Notepad.
VADs are data structures maintained by the Windows OS that “track reserved or committed, virtually contiguous collection of pages”. These can basically be thought of as chunks of memory pages used for a common purpose and containing extra meta-information on top of the raw memory contents.
I created a plugin file under volatility3/volatility3/plugins/windows/notepad.py which implements the ReadNotepad class. As per Volatility documentation, a plugin class has to inherit from plugins.PluginInterface and must implement a get_requirements method. Another requirement I came across, was that the class must contain a _required_framework_version attribute, specifying the Volatility 3 version to work with (2.0.0 in my case).
As per the requirements, the followings were needed for my plugin:
TranslationLayerRequirement: this specifies that a translation layer is required. As far as my understanding goes, this is a layer that translates actual physical memory content to virtual memory, taking care or reassembling memory that’s not necessarily stored contiguously in RAM, but belong to the same virtual memory regions.SymbolTableRequirement: In my case, this imports the Windows kernel symbols.PluginRequirement: This lists out the plugins which I wanted to build on. In my case, I neededpslistto find the Notepad process PID, andvadinfoto list the VADs in our process of interest.
All said and done, this is what the class definition and requirements look like.
class ReadNotepad(plugins.PluginInterface):
"""Gets text off of Notepad heap"""
_required_framework_version = (2, 0, 0)
@classmethod
def get_requirements(cls):
return [
requirements.TranslationLayerRequirement(name = 'primary',
description = 'Memory layer for the kernel', architectures = ["Intel32", "Intel64"]),
requirements.SymbolTableRequirement(name = "nt_symbols",
description = "Windows kernel symbols"),
requirements.PluginRequirement(name = 'pslist',
plugin = pslist.PsList, version = (2, 0, 0)),
requirements.PluginRequirement(name = 'vadinfo',
plugin = vadinfo.VadInfo, version = (2, 0, 0))
]
A run method must also be implemented. This is the method that will be called when the plugin is invoked, it must return a TreeGrid structure, which Volatility will then take care of pretty-printing. The TreeGrid structure, however, is generally populated by a _generator method, which is then where the work really takes place. Here’s the run method for my class.
def run(self):
return renderers.TreeGrid([("Content", str)], self._generator())
Moving on, the first task to accomplish is to find the right process to work on. This is done through the pslist plugin, and I feel this is one of those situations where Volatility documentation could use some love. The pslist plugin implements the PsList class, which returns a TreeGrid as a result of its run method like all plugins have to. However, the pretty text representation isn’t what you want when processing the pslist output. Instead, you want an iterable object containing EPROCESS objects (Volatility internal representation of a process). This can be achieved with a list_processes function defined in PsList which is not documented anywhere. To understand how the function worked, and what to pass to it as arguments, I had to dig through the implementation of other plugins to find useful references.
In any event, the function takes self.context (not sure what this is), the memory translation layer, the symbols, and a filter function callback as arguments. After some digging, I found out that the filter function is basically meant to return True when something is passed to it that we want to exclude. In other implementations this is used, for example, to exclude PIDs from processing. In our case, we don’t want to do any filtering so the function always returns False.
After that, each EPROCESS is checked to see if the ImageFileName (aka the name of the file on disk the process was started from) matches “notepad.exe”. If so, the EPROCESS object is returned. Some casting is needed to convert the ImageFileName attribute to native Python strings.
def filter_func(self, x):
False
def find_PID(self):
procs = pslist.PsList.list_processes(self.context, self.config['primary'], self.config['nt_symbols'], filter_func = self.filter_func)
for proc in procs:
name = proc.ImageFileName.cast("string", max_length = proc.ImageFileName.vol.count, errors = 'replace')
if name == "notepad.exe":
return proc
Now that we have our process object at hand, we need to list out all the VADs for it. This can be done with the vadinfo plugin. For each VAD we get some useful info such as the start, end, permissions, file on disk mapped in memory (if present), …
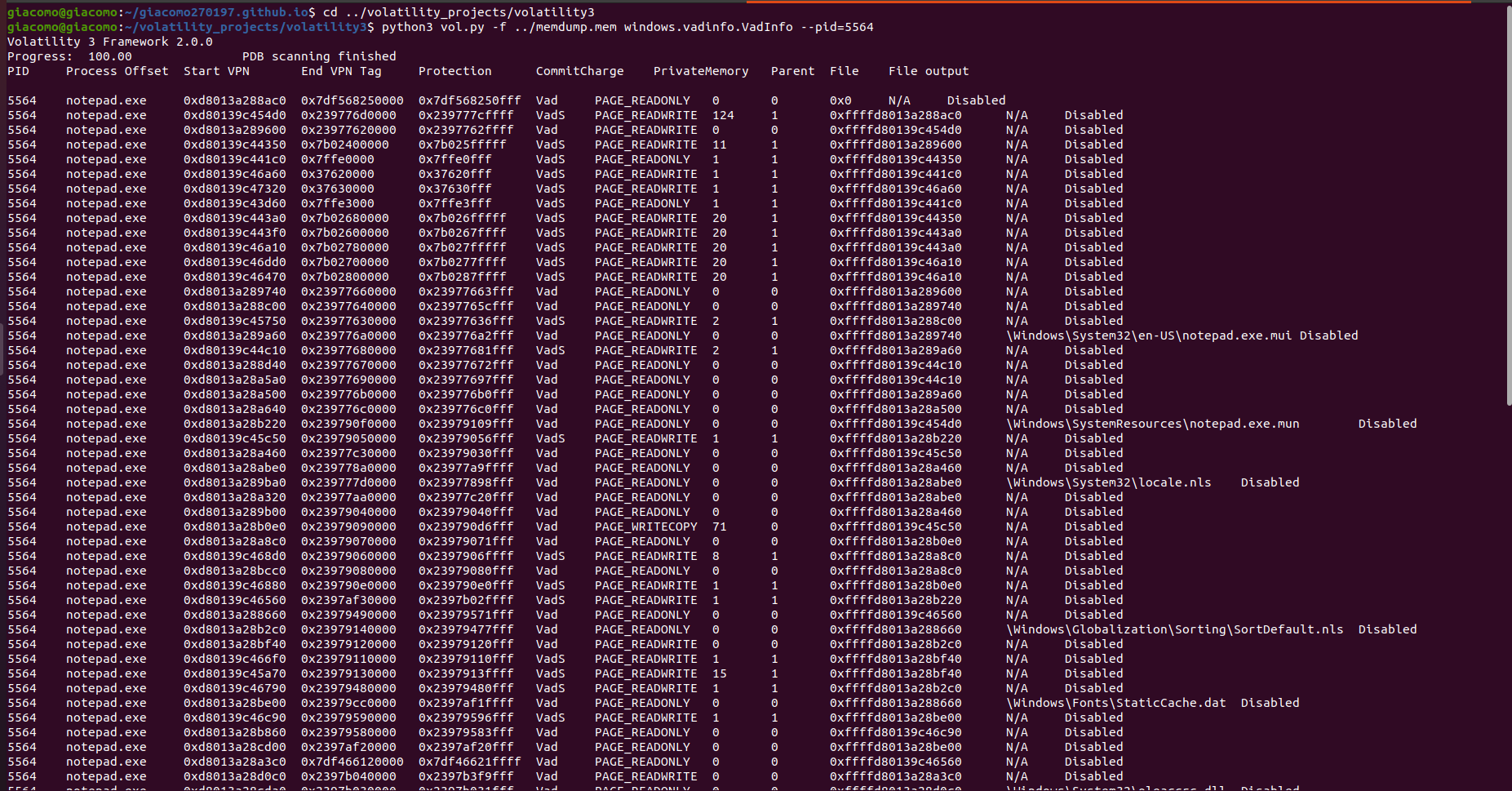
The VadInfo class in the vadinfo plugin implements the list_vads method, which takes an EPROCESS and a filter function as arguments, and returns a list of VAD objects. The filter function works the same as the one for list_processes.
def get_VADs(self, proc):
return vadinfo.VadInfo.list_vads(proc, filter_func = self.filter_func)
Another useful feature of the vadinfo info plugin is the --dump flag, which allows dumping VADs to disk. After doing that (and after some searching), this shows up in the VAD that starts at offset 0x239776d0000.
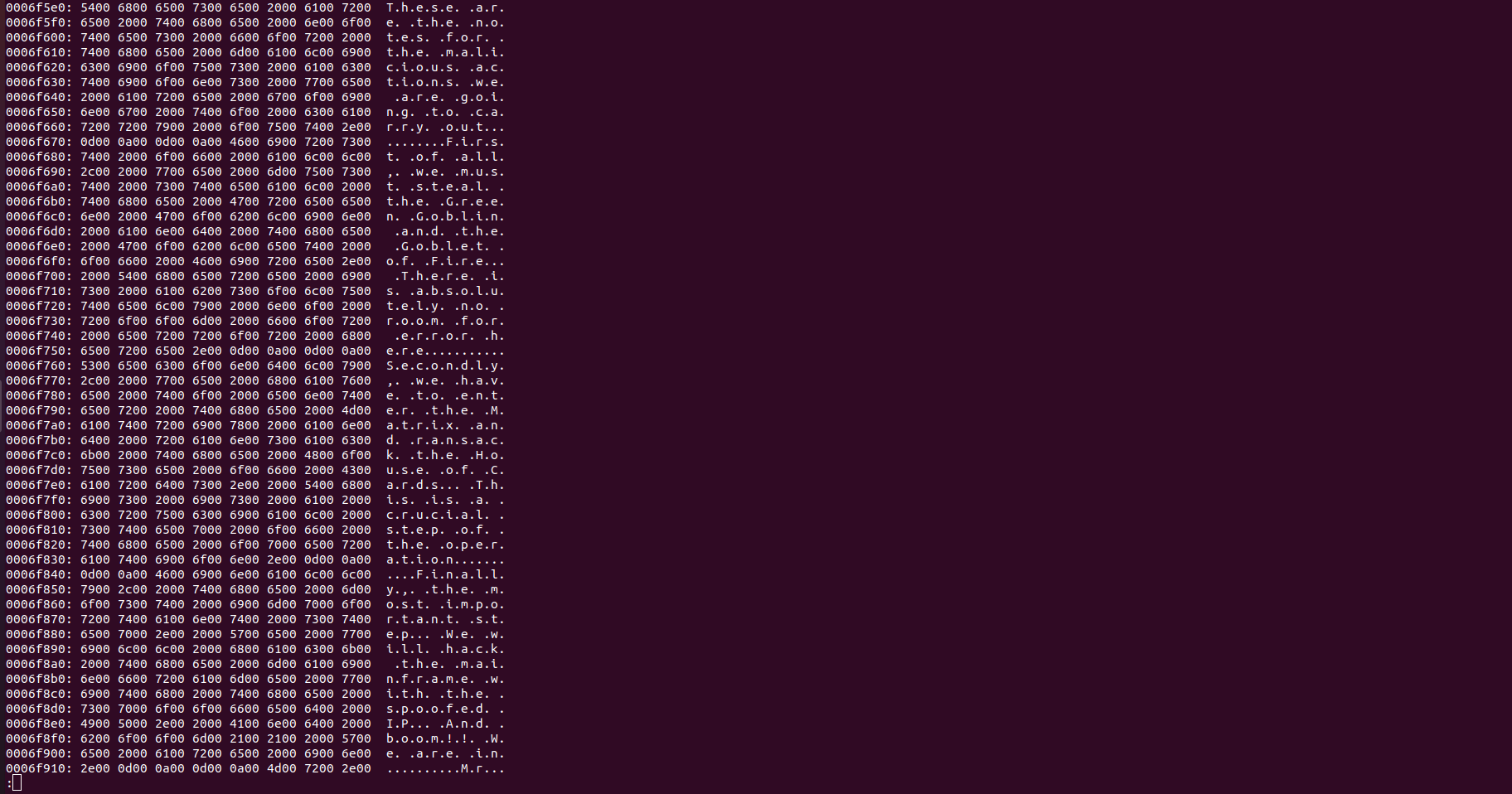
This is great! Now that we know the text is in the memory dump, all that’s left to do is to pass each VAD to a function that looks for the text. This is the implementation for it.
def detect_text(self, vad, proc):
text_start = b"\x54\x00\x68\x00\x65\x00\x73\x00\x65\x00"
text_end = b"\x74\x00\x2c\x00\x20\x00\x6f\x00\x75\x00\x74\x00"
proc_layer_name = proc.add_process_layer()
proc_layer = self.context.layers[proc_layer_name]
vad_content = b""
chunk_size = 1024 * 1024 * 10
offset = vad.get_start()
while offset < vad.get_end():
to_read = min(chunk_size, vad.get_end() - offset)
vad_content += proc_layer.read(offset, to_read, pad = True)
offset += to_read
start_search_result = vad_content.find(text_start)
if start_search_result != -1:
end_search_result = vad_content.find(text_end, start_search_result)
return [True, start_search_result, end_search_result, vad_content[start_search_result:end_search_result+1]]
return [False, -1, -1]
“Hey, that’s cheating!” I hear you say. That’s true somewhat, the function looks for the UTF-16 encoding of the first (“These”) and last (“Robot”) words of the known text, and if the words are found the function returns True, the start and end offsets, and everything in between them. Of course this only works with known text, but distinguishing between user input and other strings present in memory isn’t really the point of this experiment.
I wasn’t sure how to read bytes from memory (again, the documentation for Volatility could use some work) so I checked the vadinfo plugin. As we saw earlier, the plugin has the capability of dumping memory content to disk so it must be able to read bytes from memory. As expected, the VadInfo class implements a vad_dump method from which I took the memory reading implementation above.
All that’s left is to put it all together in the _generator method and test it out. This is what the method looks like.
def _generator(self):
proc = self.find_PID()
vads = self.get_VADs(proc)
for vad in vads:
res = self.detect_text(vad, proc)
if res[0]:
content = res[3].replace(b"\x00", b"")
content = content.decode("utf-8")
yield (0, [content])
break
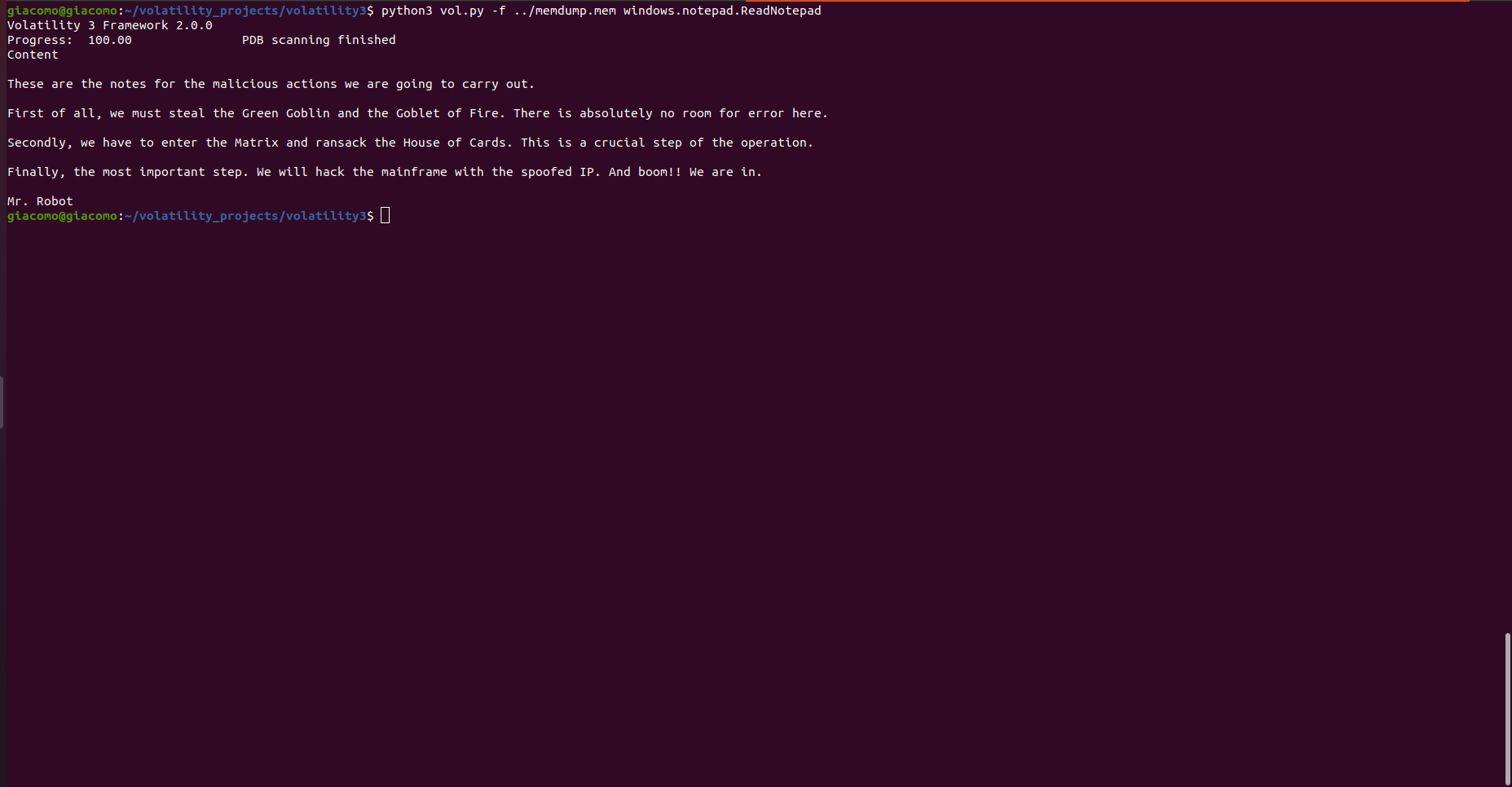
Testing time! We run the plugin, which quickly retrieves the results as expected.
At this point, the plugin is working and I could call it a day. However, the main point of the exercise in “The Art Of Memory Forensics” was to show that looking in the right places could drastically reduce the search space. In our case, we are currently looking through all the VADs, while we should really only focus on the ones that represent the heaps of the process. This is because we know the text will be stored in a heap.
In the book, this is easily done via a plugin for Volatility 2 called heaps which lists out the heaps for a given process. No such plugin is available for Volatility 3 however (nor for newer profiles on Volatility 2, is my understanding).
Well, no matter! We can easily get the information we need from the PEB of the process, right? Well kind of. That can definitely be done, and sure enough, that’s what I ended up doing, but there are some differences between Volatility 2 and 3 that made this process a bit more tedious than expected. Here are the bottlenecks I found:
- In Volatility 2, one can access the PEB for a process, as an object (
_PEB), by simply referencing the.Pebattribute on anEPROCESSobject. This is no longer possible on Volatility 3 (proc.Pebreturns a pointer instead), and the PEB has to be retrieved with the (undocumented)get_pebfunction on theEPROCESSclass. This caused some confusion and I eventually figured it out by digging deep in the bowels of the Volatility codebase. - In Volatility 2, it is possible to easily parse PEB fields and have them converted to objects to work with. I couldn’t do that in Volatility 3. To find the heaps, in Vol2, I could simply dereference a pointer to
ProcessHeapsinto an array of pointers withproc.Peb.ProcessHeaps.dereference(). This throws an error when done in Volatility 3.
So how did I find the heaps? The manual way.
First of all, I retrieved the number of heaps from the NumberOfHeaps field in the PEB. Then, I got the start of the heaps array with the ProcessHeaps attribute. Once that’s known, each entry can be iterated over and recorded.
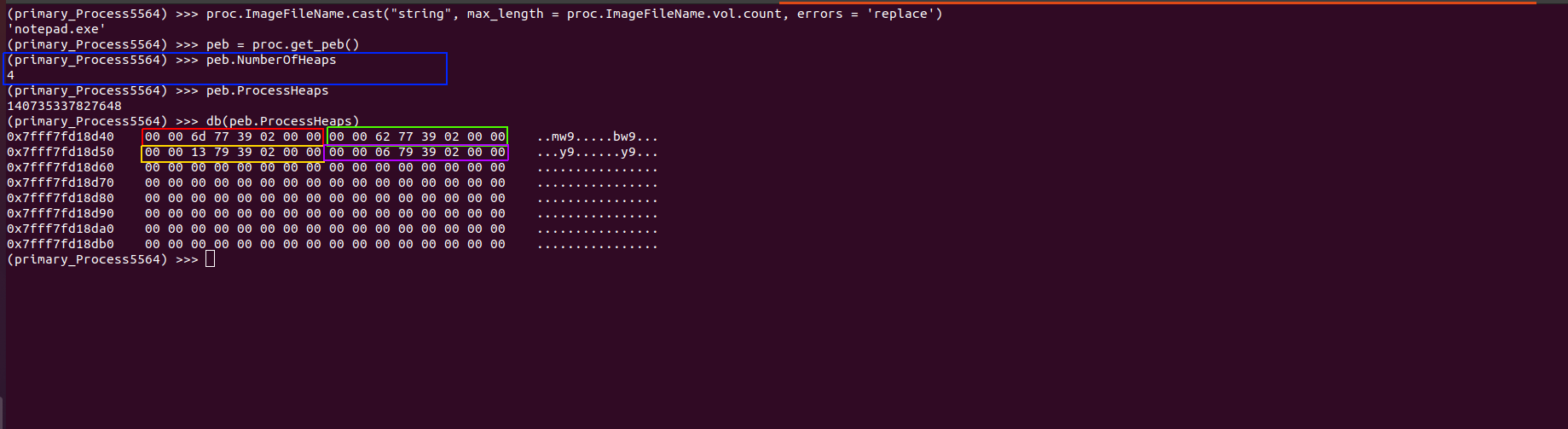
We can go over this process in volshell to visualize it a bit better. First of all, the PEB is extracted with the get_peb method on the proc object. Then, we check how many heaps there are. In this case, we can see there are four heaps in this process (highlighted in blue). We then check the address of the heaps array, and when we go ahead and dump the content at this address we see that there are indeed four addresses (in red, green, yellow, and purple) that point to the four heaps of the process. Specifically, in red, we also see the address of the VAD we know our text resides in. This is very good news!
At this point, all we need to do is to put this all in our plugin, together with some byte-to-int conversion to convert the bytestrings to address we can compare to the VAD start addresses.
def find_heaps(self, proc):
heaps = []
peb = proc.get_peb()
number_of_heaps = peb.NumberOfHeaps
process_heaps = peb.ProcessHeaps
proc_layer_name = proc.add_process_layer()
proc_layer = self.context.layers[proc_layer_name]
for _ in range(number_of_heaps):
heaps.append(int.from_bytes(proc_layer.read(process_heaps, 8, pad = False), "little"))
process_heaps += 8
return heaps
We then just need to add a few lines to our _generator to skip the search on any non-heap VAD.
def _generator(self):
proc = self.find_PID()
heaps = self.find_heaps(proc)
vads = self.get_VADs(proc)
for vad in vads:
if int(vad.get_start()) in heaps:
res = self.detect_text(vad, proc)
if res[0]:
content = res[3].replace(b"\x00", b"")
content = content.decode("utf-8")
yield (0, [content])
break
The full code can be found here.
While this is a simple plugin without any real-world application, I think it could still be very useful as a baseline for any application involving searching in memory for just about anything. The detect_function is really the only modification needed, and then this could be changed, for example, into a plugin that looks for malware configurations or encryption keys.