I recently bought the Zero2Automated course from 0verfl0w_ and Vitali Kremez, in search for a course that would cover more than just the basics of malware analysis, and that would present me with real malware to analyze. I got half-way through the course, and so far, it’s been nothing less than great.
The course offers a kind of mid-term exam/exercise. It’s a malware sample to analyze completely on your own, with no guidance whatsoever. The next few posts will cover my progress through the exercise.
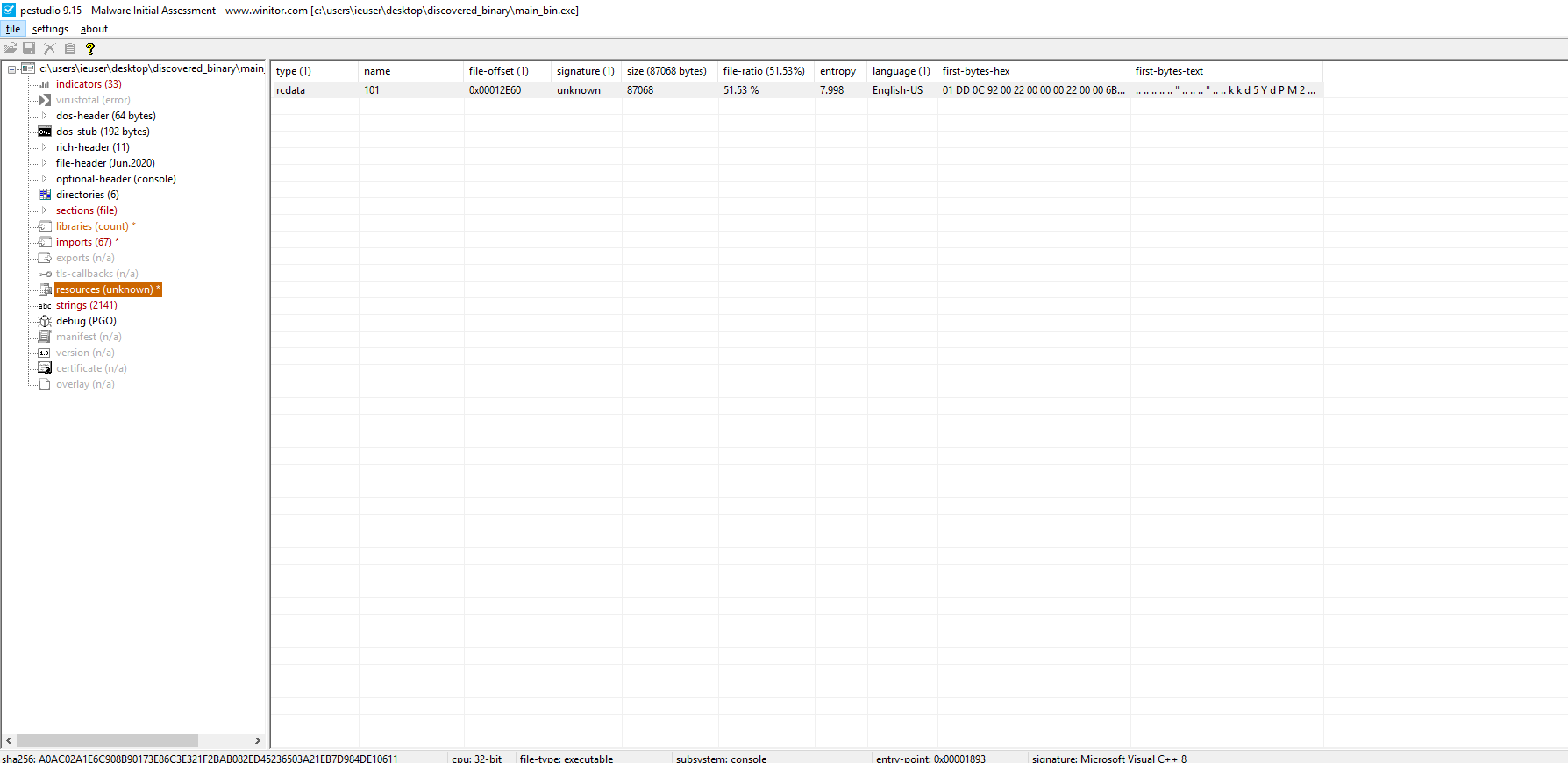
The first thing I decided to do was to pass the sample through PEStudio, to check for interesting resources, strings, imports, …. And also, to have a look at the overall entropy and confirm that the malware is packed (of course, wouldn’t be much of an exercise otherwise).
The sample only loads kernel32.dll, but it imports quite some functions from it. There’s one interesting rcdata resource that comes with the binary, 87kb in size and with very high entropy.
At this point I’m ready to have a look at the code, I load the file in Ghidra to get a quick idea of what the sample tries to do. Due to the obfuscation present in the sample I can’t really see much, but still we can get some useful information once we find the main() function
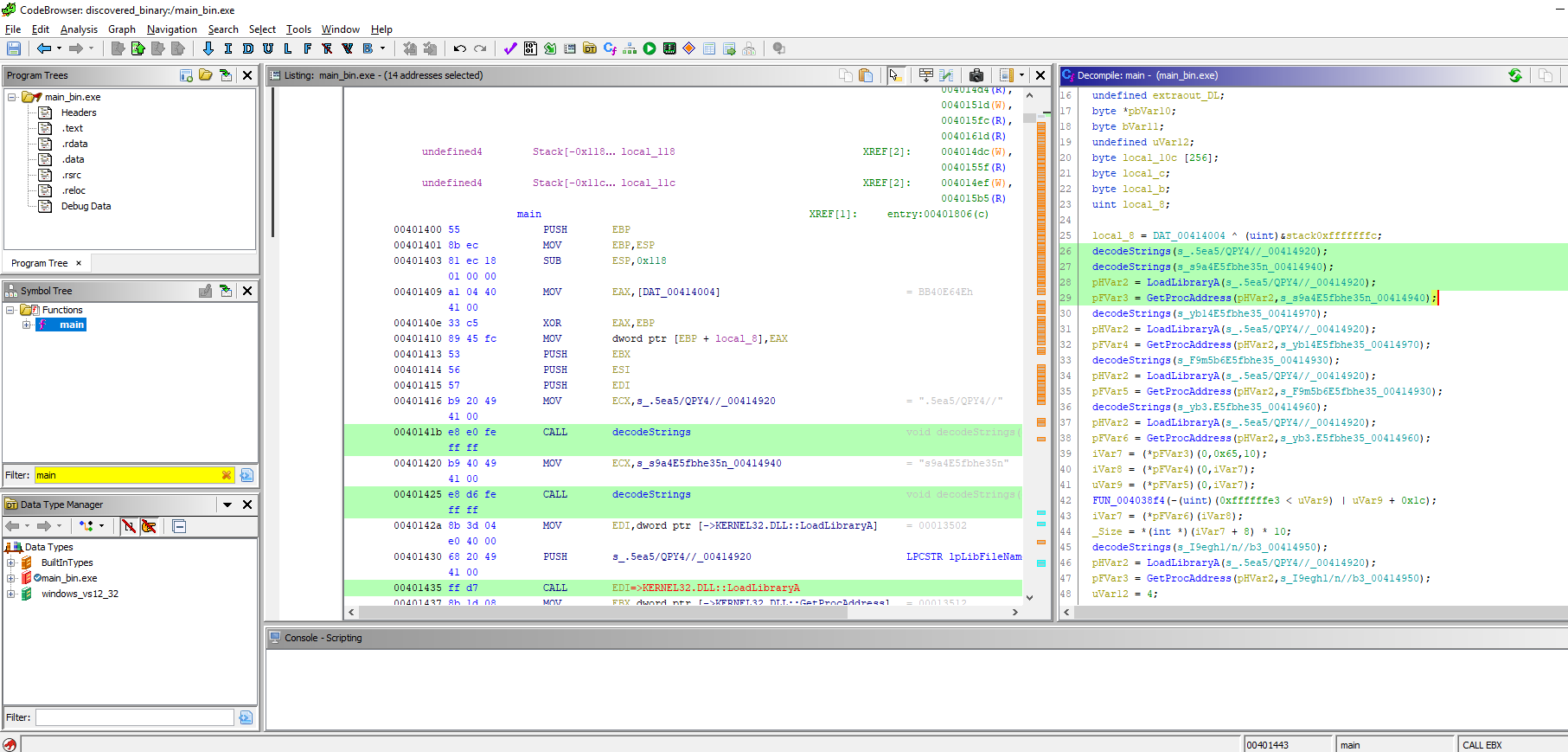
From the disassembler we can get the memory location of the main funtion. x64dbg doesn’t automatically set a breakpoint here, so we’ll go ahead and add one ourselves. We can also see that almost immediately we have calls to LoadLibrary and GetProcAddress, and before that a function is called several times with some odd strings as input. We can assume that the malware dynamically loads the required procedures, which are stored either encoded or encypted somewhere.
I didn’t find any use in doing any further static analysis, so I jumped to x32dbg directly.
The first thing the sample does is resolving some APIs calls. We could just let it do its thing and check the decoded output, but this course is about automation too (as you probably guessed from the name), and it’s hard to automate without knowing the encoding routines. So, I went ahead and reverse engineered the decoding function. The algorithm is simple, but the function does all sort of extra things that make it look more complex than what it actually is. There are two main parts to the routine. The first one does nothing but restoring some valus in memory, the second one does the actual decoding.
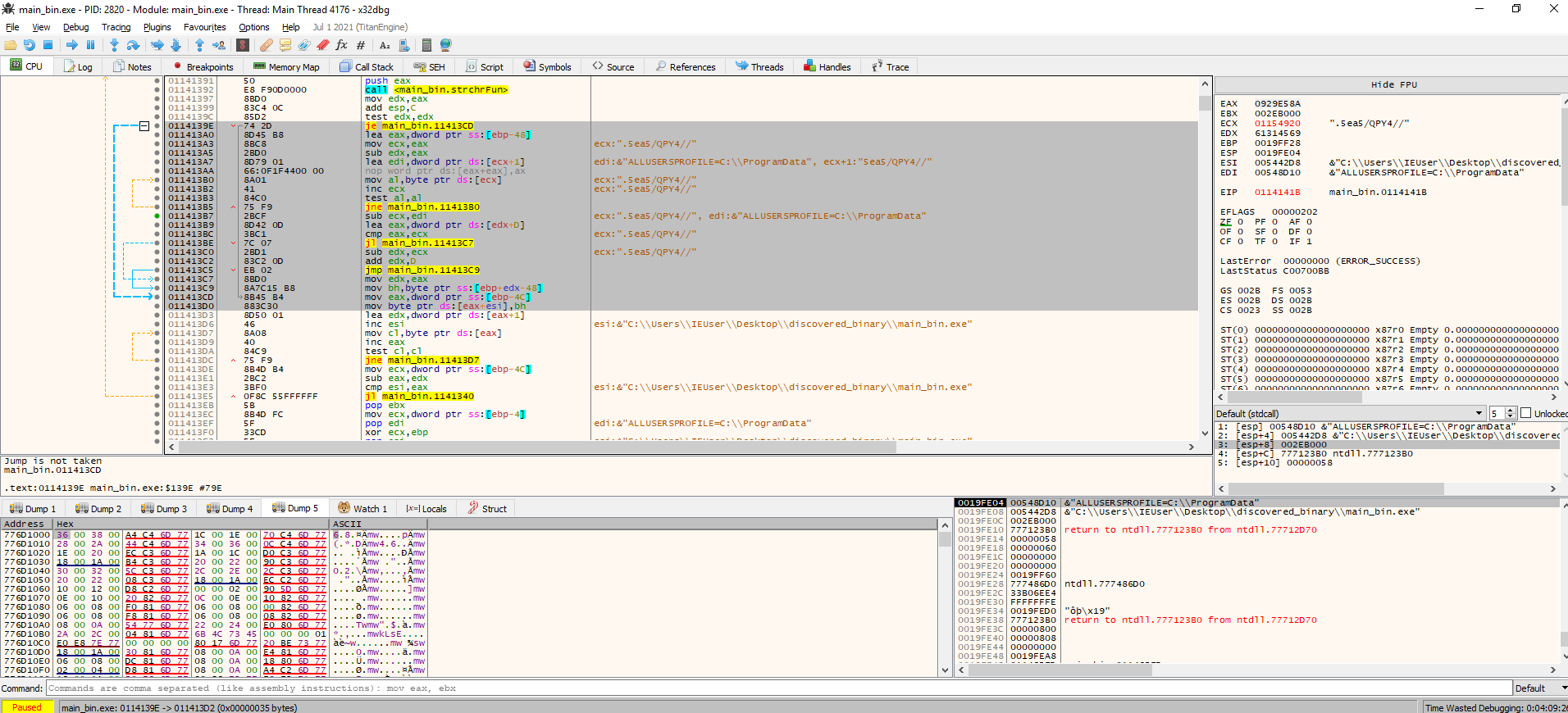
The highlighted bit in the debugger is where the magic all happens. Each letter of the encoded string is in a lookup table, some calculation based on its positioning are done, and the result is a pointer to a location in the same table that represents the original charachter. I wrote a little bit of Python to decode each string.
lookup = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ01234567890./="
encoded = "your_encoded_string"
decoded = []
for x in encoded:
locator = lookup.find(x)
length = len(lookup)
cnt = locator + 13
if cnt >= length:
position = locator - length + 13
else:
position = cnt
decoded.append(lookup[position])
print(decoded.join(""))
If we keep single stepping through the sample, we see that it immediately resolves calls to FindResourceA, LoadResource, SizeOfResource, and LockResource. This confirms our initial hypothesis about something interesing lying in the rcdata resource we found.
After loading the resource, the sample resolves VirtualAlloc, and it uses it to allocate a region of 4096 bytes in its own memory. If we keep an eye on the return address of VirtualAlloc, we can see that it soon gets filled with random looking data.
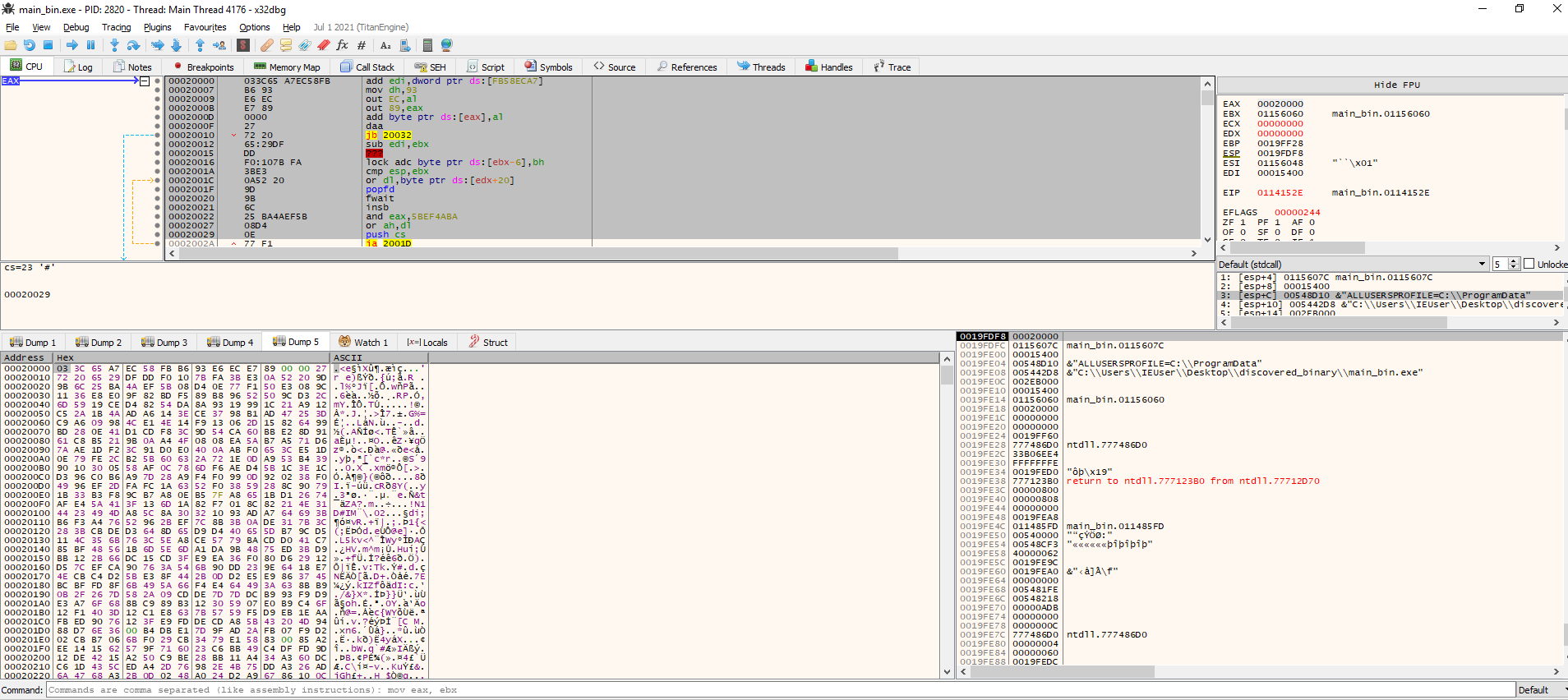
As you can see, the content of the memory region does not look like shellcode (if I follow it in the disassebler I get some weird instructions, see highlighted), so I have to assume this is more obfuscated data. We will keep an eye on the memory dump to see if any call modifies it.
Almost immediately we stumble across what’s very clearly an RC4 decytption routine (highlighted is the initialization).
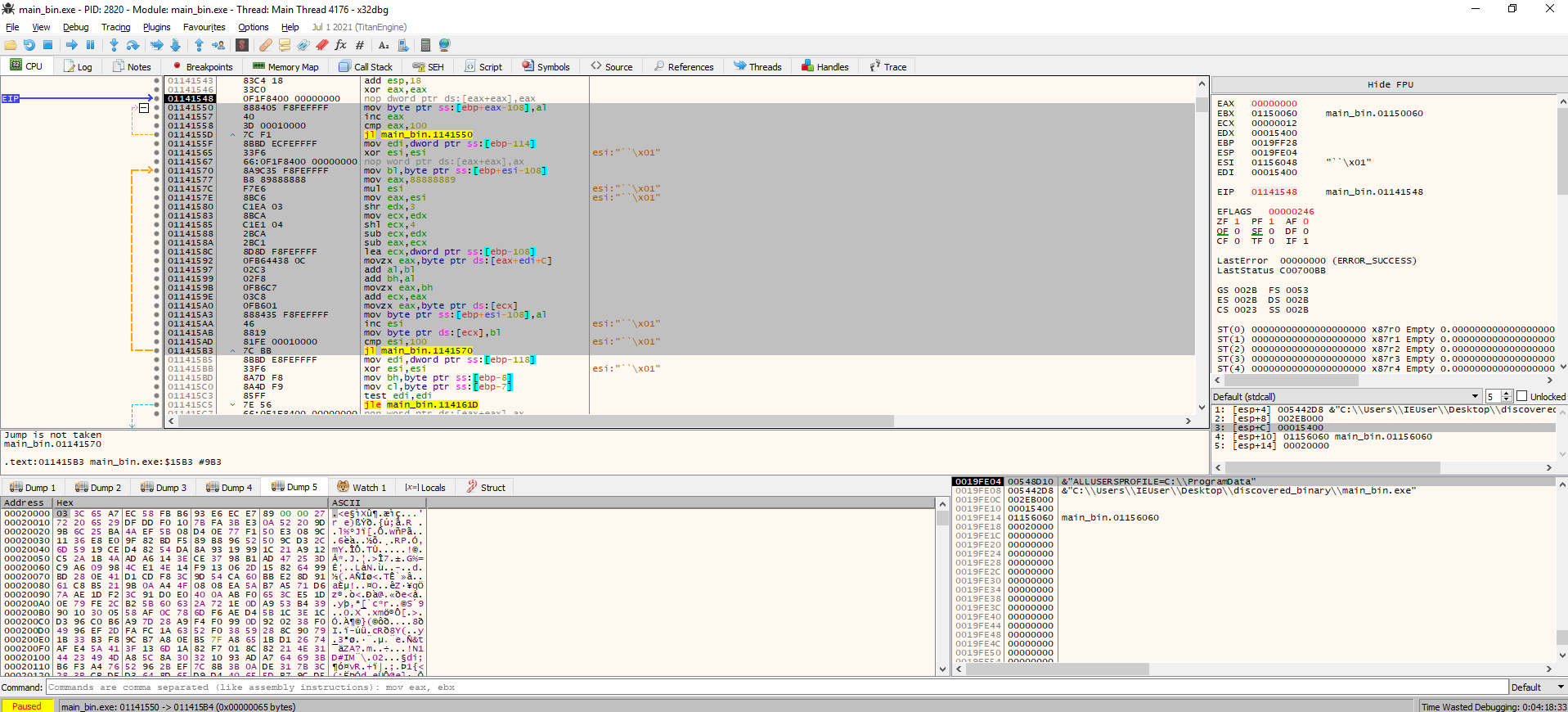
We quickly retrieve the key located at ebx-108 (see memory location 0114158C): kkd5YdPM24VBXmi.
At this point I am pretty confident in the assumption that the blob of data we saw earlier is RC4 encypted, and that this decryption routine will reveal its contents. Sure enough, we skip to the end of the decryption loop and we are greeted with a PE file!

This can also be atomated by retrieving the ancypted data and running some Python decryption like so
from Crypto.Cipher import ARC4
key = b'kkd5YdPM24VBXmi'
cipher = ARC4.new(key)
f.close()
f = open("encrypted.bin", "rb")
content = f.read()
out = chipher.decrypt(content)
We could dump this out immediately, but as of now we still have no certainty that this is indeed the executable execution will be passed to, so we wait and see what the malware does with it.
Next, the sample gets its own path with GetModuleFileName and resolves and loads CreateProcessA. This is then called to spawn a new process, which will likely be the host of the new PE we just decrypted in memory.
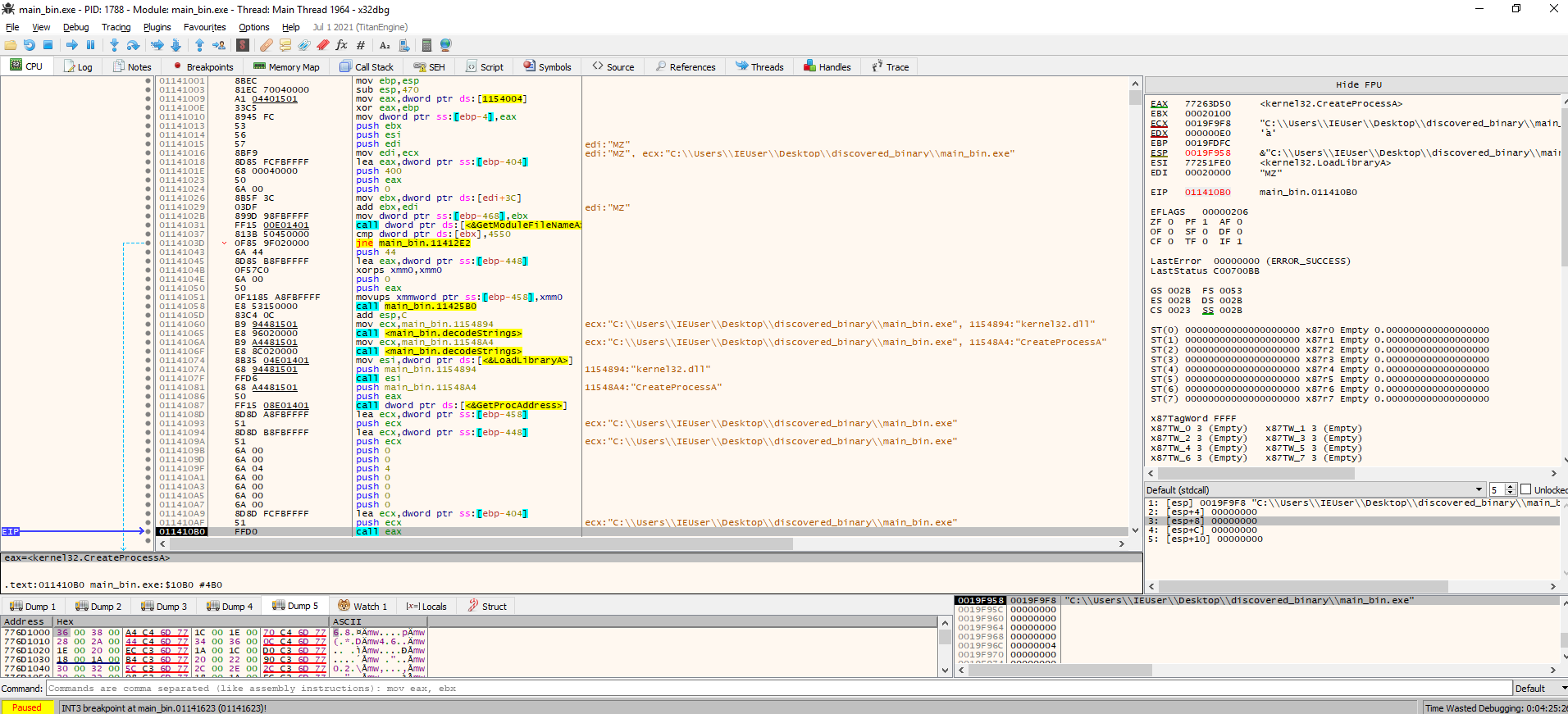
After this, it seems that the malware completely replaces the executable loaded in the new processes with the one it decrypted from resources starting from the base address. It first resolves and loads GetThreadContext, ReadProcessmemory (not sure why, maybe to read the PEB), WriteProcessMemory, and VirtualAllocEx.
Finally, the sample allocates 98kb in the target process, starting from the base address (00400000). It then writes the headers (WriteProcessMemory is located at ebp-464) and it enters a loop to write each section where needed.
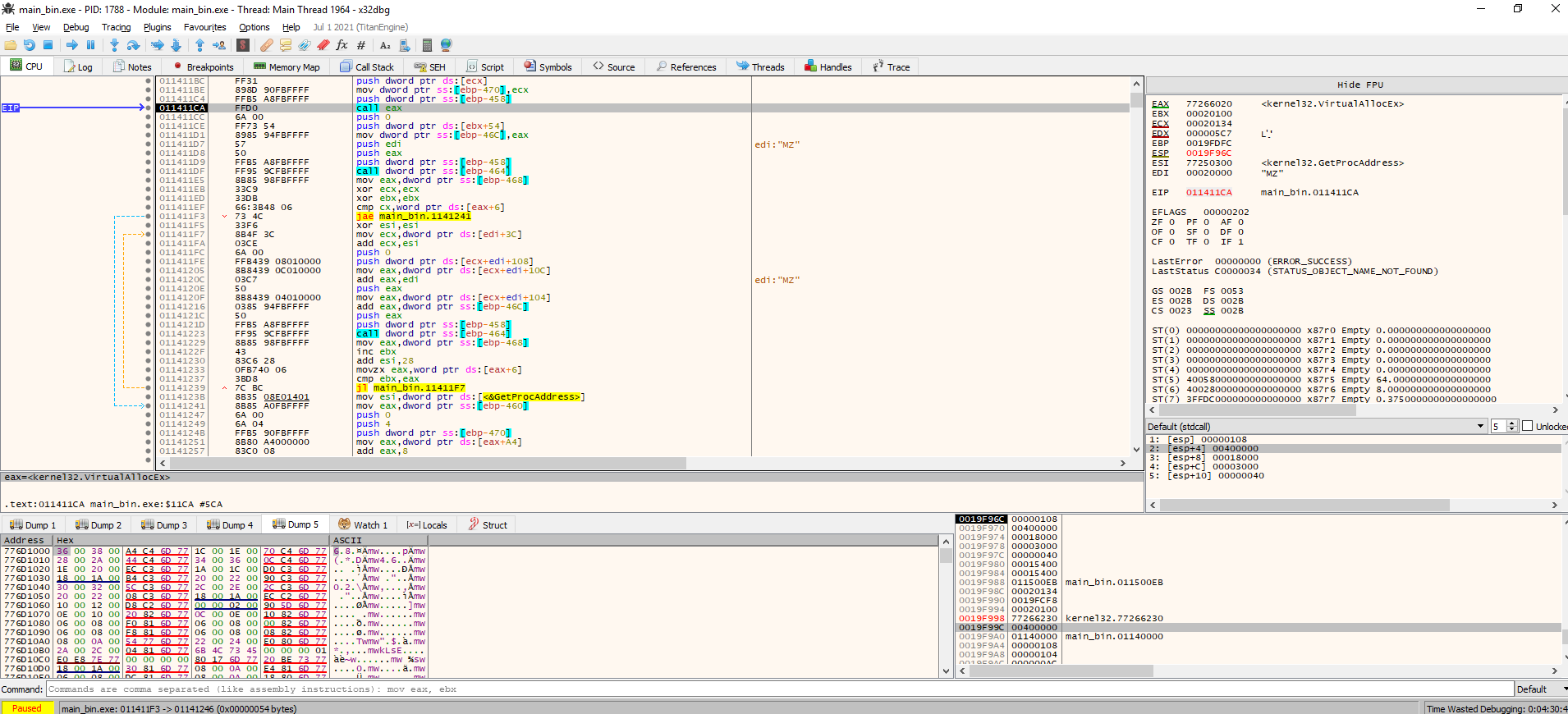
At this point we can be certain that the decypted PE file was indeed the unpacked payload. Instead of dumping the PE from our sample memory, we can go and directly dump it from the second process memory, right before ResumeThread is called. This way we can be sure we are getting a complete and uncorrupted executable (since it was ready to run).
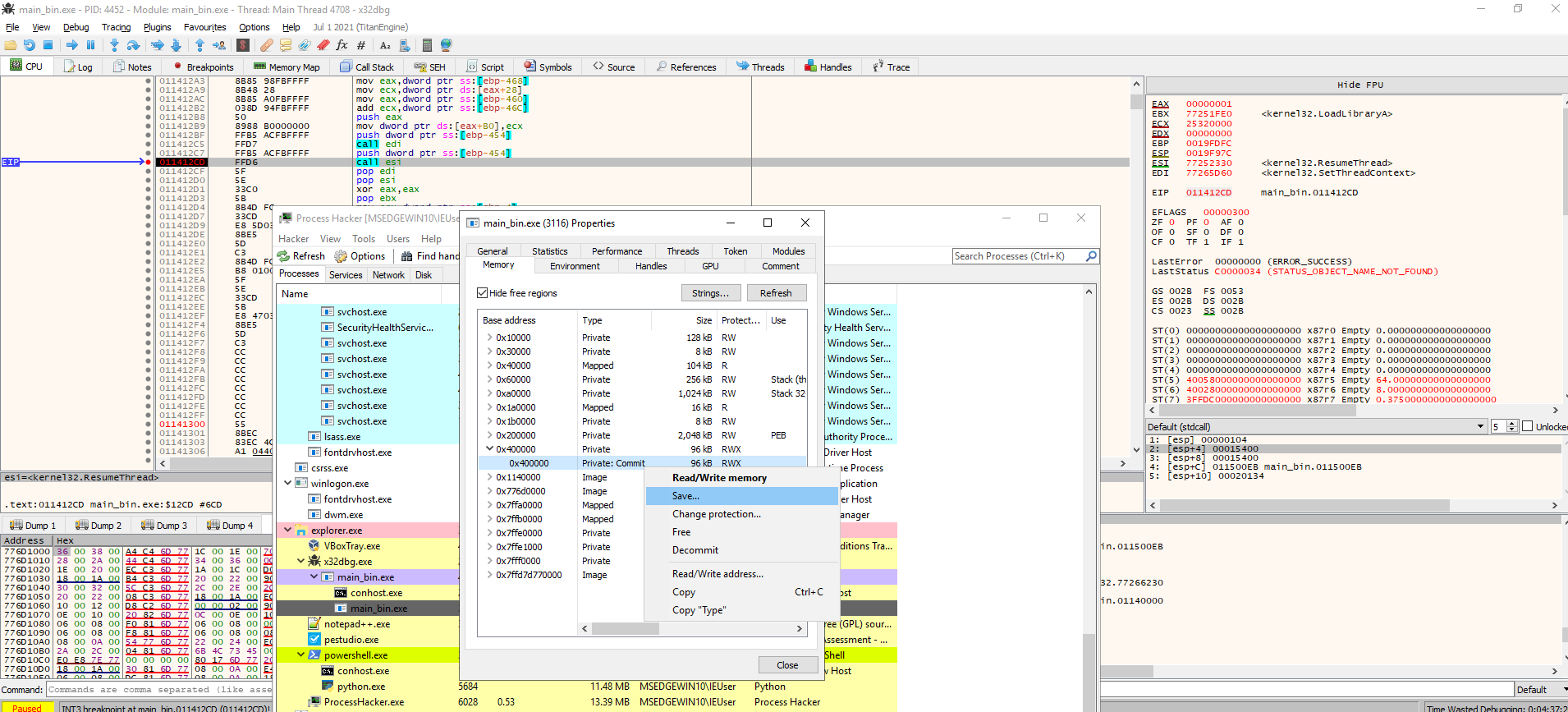
Now if we check the imports, they are going to be all broken, since we pulled the executable from memory, and we have it in its memory mapped form. We can fix this by adjusting the headers so that the raw addresses match the virtual ones, and by adjusting raw section sizes accordingly.
With that done, we are ready to jump into the analysis of the second stage. This will be the topic for the next post.